학습일지/DDD
[DDD] 바운디드 컨텍스트
Merge Log
2025. 9. 22. 11:46
하위 도메인의 중요성
- 처음 도메인을 만들때 하위 도메인의 정보는 무시하고 단일 모델만을 생각하여 완벽하게 도메인을 만들려는 실수를 저지른다
- 그러나 한 도메인은 다시 여러 하위 도메인으로 구분되기 때문에 한 개의 모델로 여러 하위 도메인을 모두 표현하려고 시도하면 오히려 맞지 않는 모델을 만들게 된다
- 예를 들어 "상품" 이라고 했을때 카탈로그 도메인에서는 상품은 상품 이미지, 상품명, 상품 가격, 옵션 목록 등과 같은 상품 정보가 위주이다
- 재고 관리 도메인에서는 상품은 실존하는 개별 객체를 추적하기 위한 목적으로 사용한다
- 즉 카탈로그에서는 물리적으로 한 개인 상품이 재고 관리 도메인에서는 여러 개 존재할 수 있다
- "회원" 또한 회원 도메인에서는 회원 이자만 주문 도메인에서는 주문자, 배송 도메인에서는 보내는 사람이라고 부르기도 한다
- 하위 도메인마다 사용하는 용어가 다르기 때문에 올바른 도메인 모델을 개발하려면 하위 도메인마다 모델을 만들어야 한다
- 각 모델은 명시적으로 구분되는 경계를 가져서 섞이지 않도록 해야 한다
- 모델은 특정한 컨텍스트(문맥) 하에서 완전한 의미를 갖는다
- 이렇게 구분되는 경계를 갖는 컨텍스트를 DDD 에서는 바운디드 컨텍스트(Bounded Context) 라고 부른다
바운디드 컨텍스트
- 모델의 경계를 결정하며 한 개의 바운디드 컨텍스트는 논리적으로 한 개의 모델을 갖는다
- 바운디드 컨텍스트는 용어를 기준으로 구분한다
- 카탈로그 컨텍스트와 재고 컨텍스트는 서로 다른 용어를 사용하므로 이 용어를 기준으로 컨텍스트를 분리할 수 있다
- 바운디드 컨텍스트는 실제로 사용자에게 기능을 제공하는 물리적 시스템으로 도메인 모델은 이 바운디드 컨텍스트 안에서 도메인을 구현한다
- 이상적으로 하위 도메인과 바운디드 컨텍스트가 일대일 관계를 가지면 좋겠지만 현실은 그렇지 않을 때가 많다
- 여러 하위 도메인을 하나의 바운디드 컨텍스트에서 개발할 때 주의할 점은 하위 도메인의 모델이 섞이지 않도록 하는 것 이다
- 여러 하위 도메인이 복잡하게 보이므로 단일 모델로 통합하는 실수를 하게된다 → 결과적으로 도메인 모델이 개별 하위 도메인을 제대로 반영하지 못해서 하위 도메인별로 기능을 확장하기 어렵게 된다
- 한 개의 바운디드 컨텍스트가 여러 하위 도메인을 포함하더라도 하위 도메인마다 구분되는 패키지를 갖도록 구현해야 한다
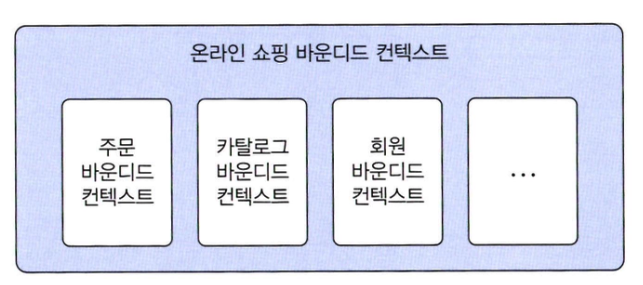
- 바운디드 컨텍스트는 구현하는 하위 도메인에 알맞는 모델을 포함해야 한다
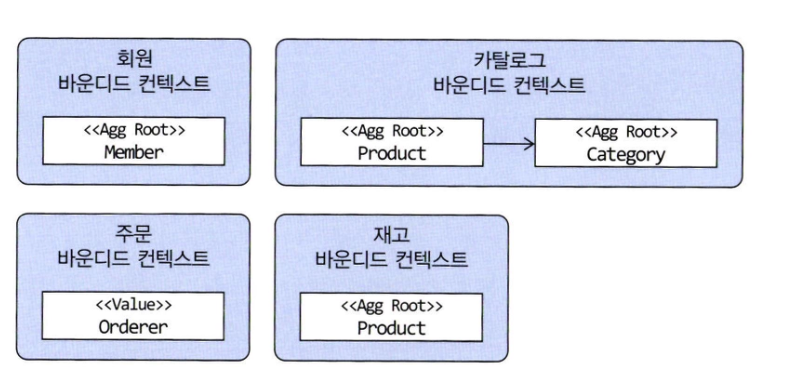
- 같은 회원이라도 회원 바운디드 컨텍스트와 주문 바운디드 컨텍스트가 갖는 모델은 다르다
- 회원의 Member 는 애그리거트 루트이지만 주문의 Orderer 는 밸류가 된다
- 마찬가지로 같은 상품이라도 카탈로그와 재고 바운디드 컨텍스트는 다른 모델을 갖게된다
- 카탈로그의 Product 는 상품이 속해야하는 Category 와 연관을 맺지만 재고의 Product 는 카탈로그의 Category 와 연관을 맺지 않는다
같은 도메인(엔티티)의 대한 데이터 일관성은?
- 위 예시를 보았을때 Member 와 Orderer 는 각각 도메인(엔티티) / 밸류 형태이다
- 즉 생성에 대한 라이프 사이클이 다르다
- 그러나 상품(Product) 같은 경우 카탈로그 바운디드 컨텍스트에서도 관리하고 재고 바운디드 컨텍스트에서도 관리해야한다
- 이 경우 상품이 생성되면 두 바운디드 컨텍스트에 데이터 동기화를 해야 한다
- 이때 여러가지 방안을 생각할 수 있다
- 먼저 "각 바운디드 컨텍스트는 자기 DB 를 소유하는것이 맞다"
- 카탈로그 바운디드 컨텍스트 :
catalog.products,catalog.categories, ... - 재고 바운디드 컨텍스트 :
inventory.items(또는inventory.products), ... - 즉 물리적으로 테이블이 분리되는 것이 일반적이다 (스키마 분리 or 인스턴스 분리)
- 같은 Product 라도 저장되는 컬럼/인덱스/제약이 다르므로 필요한 정보만 저장한다
- 카탈로그 바운디드 컨텍스트 :
- 만약 하나의 Product 가 생성되면 두 테이블 모두 Insert/Update 해야 하는가?
- 동일 트랜잭션에서 양쪽 DB에 동시 쓰기(dual write) 를 하지 않는다
- 소유(Owner) 컨텍스트가 원장을 가지고, 나머지는 이벤트 구독 형태로 자기 모델을 갱신해야 한다
- 상태 변경시 도메인 이벤트 발행 혹은 소유 컨텍스트의 API 호출(ACL/Anti-Corruption Layer) 등이 있다
바운디드 컨텍스트 구현
- 바운디드 컨텍스트가 도메인 모델만을 포함하는 것은 아니다
- 바운디드 컨텍스트는 도메인 기능을 사용자에게 제공하는 데 필요한 표현 영역, 응용 서비스, 인프라스트럭처 영역을 모두 포함한다
- 도메인 모델의 데이터 구조가 바뀌면 DB 테이블 스키마도 함께 변경해야 하므로 테이블도 바운디드 컨텍스트에 포함된다
- 만약 리뷰 같은 간단한 기능을 제공하는 경우 굳이 도메인까지 생성할 필요 없이 서비스-DAO 구조를 사용할 수도 있다
- 도메인 기능 자체가 단순하면 서비스-DAO 로 구성된 CURD 방식을 사용해도 코드 유지보수에 문제가 될 것 같아 보이진 않는다
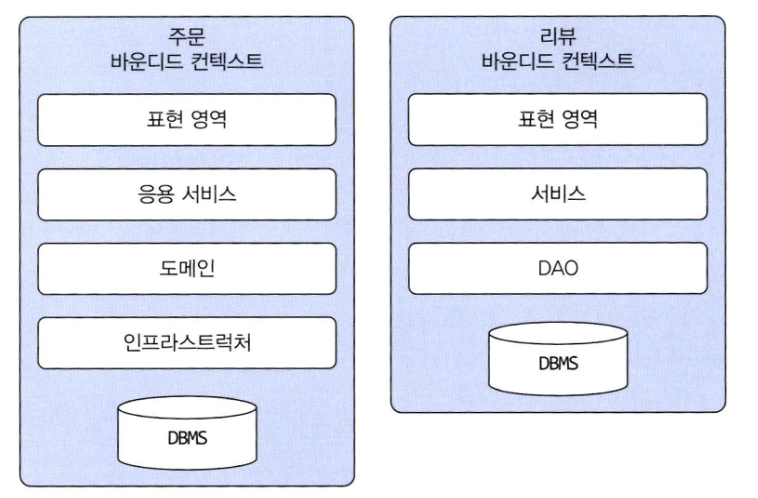
- 도메인 기능 자체가 단순하면 서비스-DAO 로 구성된 CURD 방식을 사용해도 코드 유지보수에 문제가 될 것 같아 보이진 않는다
바운디드 컨텍스트 간 통합 (카탈로그와 추천 기능)
- 기존 카탈로그 바운디드 컨텍스트에 추천을 위한 추천 바운디드 컨텍스트가 포함되었다고 가정해보자
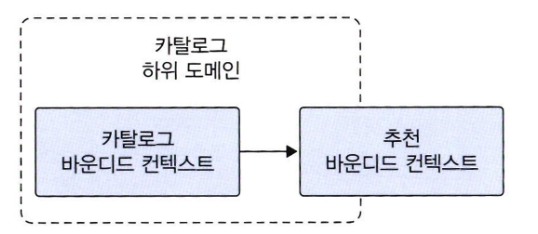
- 추천 기능은 아래의 기능을 수행해야 한다
- "사용자가 제품 상세 페이지를 볼 때, 보고 있는 상품과 유사한 상품 목록을 하단에 보여줘야 한다"
- 사용자가 카탈로그 바운디드 컨텍스트에 추천 제품 목록을 요청하면 카탈로그 바운디드 컨텍스트는 추천 바운디드 컨텍스트로부터 추천 정보를 읽어와 추천 제품 목록을 제공한다
- 이때 카탈로그 컨텍스트와 추천 컨텍스트의 도메인 모델은 서로 다르다
- 이 경우 카탈로그 바운디드 컨텍스트를 통해서 추천 바운디드 컨텍스트의 정보를 받아야 하므로 다음과 같이 카탈로그의 모델을 기반으로 하는 도메인 서비스를 만들 수 있다
public interface ProductRecommendationService {
List<Product> getRecommendationsOf(ProductId id);
}- 도메인 서비스를 구현한 구현체는 인프라스트럭쳐 영역에 위치해야 한다
- 이 클래스는 외부 시스템과의 연동을 처리하고 외부 시스템의 모델과 현재 도메인 모델간의 변환을 책임진다

- 이 클래스는 외부 시스템과의 연동을 처리하고 외부 시스템의 모델과 현재 도메인 모델간의 변환을 책임진다
RecSystemClient는 외부 추천 시스템이 제공하는 REST API 를 이용해서 특정 상품을 위한 추천 상품 목록을 로딩한다 그 후 카탈로그 바운디드 컨텍스트의 도메인 모델로 변환한다- REST API 를 호출하는 것은 두 바운디드 컨텍스트를 직접 통합하는 방법이다. 직접 통합하는 대신 간접적으로 통합하는 방법도 있다
- 대표적인 간접 통합 방식이 메시지 큐를 사용하는 것 이다

- 두 바운디드 컨텍스트 간의 통합은 고객과 공급자 관계를 나타내어야 한다
- 데이터의 의존 관계에 따라 정해진다. 위 예시에서는 카탈로그가 고객이며 추천이 공급자이다
- 하류(downstream) 컴포넌트인 카탈로그 컨텍스트는 상류(upstream) 컴포넌트인 추천 컨텍스트가 제공하는 데이터와 기능에 의존한다
- 추천 시스템은 하류 컴포넌트가 사용할 수 있도록 REST API 를 제공하거나 프로토콜 버퍼(Protocol Buffers) 와 같은 것을 이용해 서비스를 제공할 수 있다
안티코럽션 계층
- 위 그림에서
RecSystemClient는 외부 시스템과의 연동을 처리하는데 외부 시스템의 도메인 모델이 내 도메인 모델을 침범하지 않도록 막아주는 역할을 한다 - 즉 내 모델이 깨지는 것을 막아주는 안티코럽션 계층이 된다
- 이 계층에서 두 바운디드 컨텍스트 간의 모델 변환을 처리해주기 때문에 다른 바운디드 컨텍스트의 모델에 영향을 받지 않고 내 도메인 모델을 유지할 수 있다
- 두 바운디드 컨텍스트가 같은 모델을 공유하는 경우도 있다
- 이렇게 함으로써 중복 설계를 막을 수 있으며 이렇게 두 팀이 공유하는 모델을 공유 커털(SHARED KERNEL) 이라고 부른다
- 임의로 모델을 변경하면 안되며 두 팀이 밀접한 관계를 유지해야 한다