학습일지/DDD
[DDD] 애그리거트
Merge Log
2025. 9. 19. 16:04
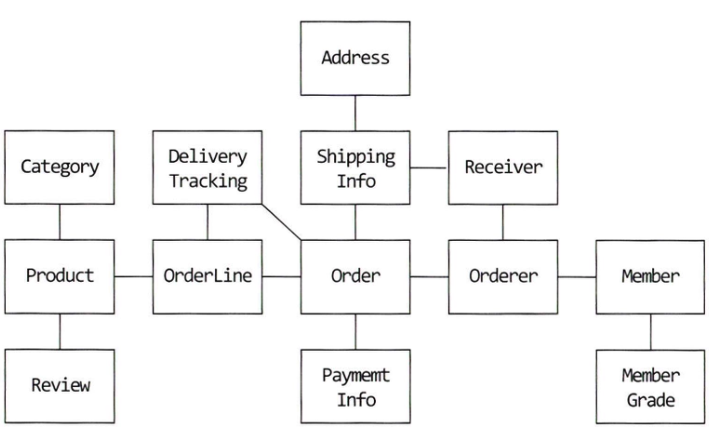
위 그림만 보고서는 한눈에 각 도메인이 어떻게 연관되어 있는지 파악하기 어렵다
이는 부분적인 모델만 이해할 수 있게 되는데 이렇게 될 경우 코드를 수정하는 것을 꺼려지게 하고 코드 변경을 최대한 회피하는 쪽으로 요구사항을 협의하게 된다
복잡한 도메인을 이해하고 관리하기 쉬운 단위로 만들려면 상위 수준에서 모델을 조망할 수 있는 방법이 필요한데 그 방법이 바로 애그리거트이다

- 애그리거트는 모델을 이해하는 데 도움을 줄 뿐만 아니라 일관성을 관리하는 기준도 된다
- 애그리거트는 관련된 모델을 하나로 모았기 때문에 한 애그리거트에 속한 객체는 유사하거나 동일한 라이프 사이클을 갖는다
- 애그리거트는 위와 같이 경계를 갖는다, 한 애그리거트에 속한 객체는 다른 애그리거트에 속하지 않는다
- 각 애그리거트는 자기 자신을 관리할 뿐 다른 애그리거트를 관리하지 않는다
- 흔히 "A가 B를 갖는다" 로 설계할 수 있는 요구사항이 있다면 A 와 B 를 한 애그리거트로 묶어서 생각하기 쉽다
- 하지만 "A 가 B 를 갖는다" 로 해석할 수 있는 요구사항이 있더라도 이것이 반드시 A와 B가 한 애그리거트에 속한다는 것을 의미하는 것은 아니다
- 그 예시가 "상품과 리뷰" 관계이다. Product 안에 Review 가 속할 수 있지만 Product 와 Review 는 함께 생성되지 않으며 함께 변경되지 않는다. 변경 주체또한 Product 는 상품 담당자라면 Review 는 고객이다
- 처음 도메인 모델을 만들기 시작하면 큰 애그리거트로 보이는 것들이 많지만, 도메인에 대한 경험이 생기고 도메인 규칙을 제대로 이해할수록 애그리거트의 실제 크기는 줄어든다
애그리거트 루트
- 애그리거트에 속한 모든 객체가 일관된 상태를 유지하려면 애그리거트 전체를 관리할 주체가 필요한데, 이 책임을 지는 것이 바로 애그리거트의 루트 엔티티이다
- 애그리거트 루트 엔티티는 애그리거트의 대표 엔티티이며 애그리거트에 속한 객체는 애그리거트 루트 엔티티에 직접 또는 간접적으로 속하게 된다
- 애그리거트 루트는 단순히 애그리거트에 속한 객체를 포함하는 것으로 끝나는 것이 아닌, 애그리거트의 일관성이 깨지지 않도록 하는 것 이다
- 이를 위해 애그리거트 루트는 애그리거트가 제공해야 할 도메인 기능을 구현한다
- 주문 애그리거트라면 배송지 변경, 상품 변경 등
- 또한 배송이 시작되기 전까지만 배송지 정보를 변경할 수 있다는 규칙이 있다면 애그리거트 루트는 이 규칙을 유지하며 행동해야 한다
- 애그리거트 외부에서 애그리거트에 속한 객체를 직접 변경하면 안 된다. 이것은 애그리거트 루트가 강제하는 규칙을 적용할 수 없어 모델의 일관성을 깨는 원인이 된다
ShippingInfo shipping = order.getShippingInfo();
shipping.setAddress(newAddress);애그리거트 루트의 기능 구현
- 애그리거트 루트는 애그리거트 내부의 다른 객체를 조합해서 기능을 완성한다.
- 예를 들어 Order 는 총 주문 금액을 구하기 위해 OrderLine(한 주문의 묶인 각 주문정보) 목록을 사용한다
- 애그리거트 루트가 구성요소의 상태만 참조하는 것이 아닌 기능 실행을 위임하기도 한다
트랜잭션 범위
- 트랜잭션 범위는 작을수록 좋다
- 한 트랜잭션이 한 개 테이블을 수정하는 것과 세 개의 테이블을 수정하는 것을 비교하면 트랜잭션 충돌을 막기 위해 잠그는 대상이 달라진다
- 한 개 테이블의 한해서만 잠금을 처리하지만 세 개의 테이블에 대해서는 세 개의 잠금을 처리해야한다
- 잠금 대상이 많아진다는 것은 그만큼 동시에 처리할 수 있는 트랜잭션 개수가 줄어든다는 것을 의미하고 이것은 전체적인 성능을 떨어뜨린다
- 한 트랜잭션에서는 한 개의 애그리거트만 수정해야 한다
- 이것은 애그리거트에서 다른 애그리거트를 변경하지 않는다는 것을 의미한다
- 즉 애그리거트가 자신의 책임 범위를 넘어서 다른 애그리거트를 관리하면 안되며 애그리거트는 최대한 서로 독립적이어야 한다
- 부득이하게 한 트랜잭션으로 두 개 이상의 애그리거트를 수정해야 한다면 애그리거트에서 다른 애그리거트를 직접 수정하지 말고 응용 서비스에서 두 애그리거트를 수정하도록 구현한다
- 혹은 팀 표준, 기술의 제약, UI 구현의 편리 등 상황에 따라 한 트랜잭션에서 여러 애그리거트를 처리하는 것을 고려할 수는 있다
애그리거트의 Repository
- 애그리거트는 개념상 완전한 한 개의 도메인 모델을 표현하므로 객체의 영속성을 처리하는 리포지터리(
Repository)는 애그리거트 단위로 존재한다 - 리포지터리는 애그리거트 전체를 저장소에 영속화해야 한다. 즉, Order 애그리거트와 관련된 테이블(OrderLine, Orderer 등)은 애그리거트 루트 뿐 아니라 매핑되는 테이블과 애그리거트에 속한 모든 구성요소에 매핑된 테이블에 데이터를 저장해야 한다
- 동일하게 애그리거트를 구하는 리포지토리 메서드는 완전한 애그리거트를 제공해야 한다
- 즉, order 애그리거트는 OrderLine, Orderer 등 모든 구성요소를 포함하는 Order 를 제공해야 한다
다른 애그리거트의 참조
- 애그리거트도 다른 애그리거트를 참조할 때가 있다. 애그리거트에서 다른 애그리거트를 참조한다는 것은 다른 애그리거트의 루트를 참조한다는 것과 같다
- JPA 를 사용하면 연관된 객체를 로딩하기도 하며 지연 로딩기능 또한 제공한다 → 이러한 편의성에는 항상 단점이 존재한다
- 한 애그리거트 내부에서 다른 애그리거트 객체에 접근할 수 있으므로 다른 애그리거트의 상태를 쉽게 변경할 수 있게된다
- 트랜잭션 범위에서 언급한 것 처럼 한 애그리거트가 관리하는 범위는 자기 자신으로 한정해야 한다
- 더불어 확장에 용이하지 않게 된다. 직접 객체를 참조하거나 JPA 말고 다른 기술을 사용할때 제약이 될 수 있다
- 직접 연관관계를 맺는 것 보다는 (직접 필드에 객체를 참조하는 것) ID 를 이용해서 다른 애그리거트를 참조하면 모델의 복잡도를 낮추고 확장에 용이하게 된다
public class Orderer {
private MemberId memberId;
...
}- 이는 애그리거트의 경계를 명확히 하고 애그리거트 간 물리적인 연결을 제거하기 때문에 모델의 복잡도를 낮춰준다
- 더불어 한 애그리거트에서 다른 애그리거트를 수정하는 문제를 근원적으로 방지할 수 있다
- 하지만 ID 간 조회를 따로 구성해야하므로 N+1 문제가 발생할 수도 있다
- 이러한 문제가 발생하지 않으려면 조회 전용 쿼리를 사용하면 된다
- 데이터 조회를 위한 별도의 Repository 를 만들고 조인을 이용해 한 번의 쿼리로 필요한 데이터를 로딩한다
- 애그리거트가 서로 다른 저장소를 사용해야 한다면 쿼리로는 해결할 수 없으며 조회 성능을 높이기 위해 캐시 등 조회 전용 기술을 따로 구성해야할 수도 있다
애그리거트를 팩토리로 활용하기
- 상점(Store) 와 상품(Product) 가 있다고 가정해보자
- 고객이 상점에 여러차례 신고를 하면 해당 상점은 상품을 등록할 수 없다
public ProductId registerNewProduct(NewProductRequest request) {
Store store = storeRepository.findById(request.getStoreId());
if (store.isBlocked()) {
throw new StoreBlockedException();
}
Product product = new Product(store.getId(), ...);
Product savedProduct = productRepository.save(product);
return new ProductId(savedProduct.getId());
}- 이 코드는 Product 를 생성 가능한지 판단하는 코드와 Product 를 생성하는 코드가 분리되어 있다
- 코드가 나빠보이진 않지만 중요한 도메인 로직이 응용 서비스에 노출되어 있으며 Store 가 Product 에 생성 가능한지 판단 및 생성하는 것은 논리적으로 하나의 도메인 기능인데 이 도메인 기능을 응용 서비스에서 구현하고 있는 것 이다
- 이 도메인 기능을 위한 별도의 도메인 서비스를 만들 수도 있지만 이 기능을 Store 애그리거트에서 구현할 수도 있다
public class Store {
public Product createProduct(...) {
if (isBlocked()) {
throw new StoreBlockedException();
}
return new Product(...);
}
}public ProductId registerNewProduct(NewProductRequest request) {
Store store = storeRepository.findById(request.getStoreId());
Product product = store.createProduct(...);
Product savedProduct = productRepository.save(product);
return new ProductId(savedProduct.getId());
}- Store 애그리거트의 createProduct() 는 Product 애그리거트를 생성하는 팩토리 역할을 한다
- 팩토리 역할을 하면서도 중요한 도메인 로직을 구현하고 있다
- 응용 서비스에서는 더 이상 Store 의 상태를 확인하지 않는다는 것이 차이점이다
- 이렇게 함으로써 Store 에 따른 Product 생성 여부를 도메인 영역의 Store 만 변경하면 되고 응용 서비스는 영향을 받지 않는다
- 즉 도메인의 응집도가 높아졌다
- 이것이 바로 애그리거트를 팩토리로 사용할 때의 장점이다
- 만약 Product 를 생성할때 알아야 하는 정보가 너무 많다고 한다면 Store 애그리거트에서 Product 애그리거트를 직접 생성하지 않고 다른 팩토리에 위임하는 방법도 있다
public class Store {
public Product createProduct(...) {
if (isBlocked()) {
throw new StoreBlockedException();
}
return ProductFactory.create(...);
}
}