파티션(Partition)
- 큐(임시로 저장할 수 있는 공간)를 여러개 늘려서 병렬 처리를 가능하게 하는 기본 단위
- 각 토픽은 하나 이상의 파티션으로 구성할 수 있다
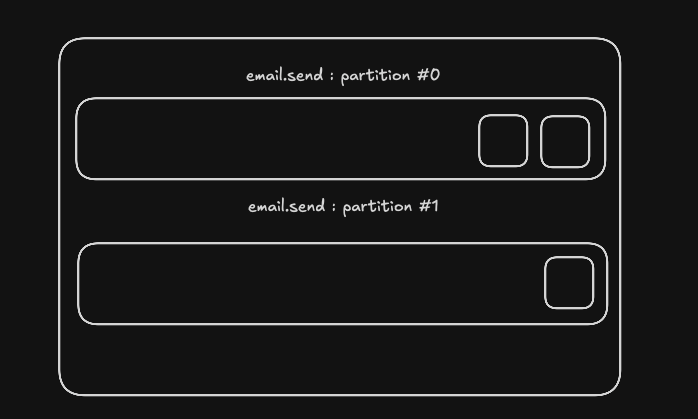
하나의 파티션은 하나의 컨슈머에게만 할당된다
- 하나의 파티션은 동일한 Consumer Group 내의 단 하나의 컨슈머에게만 할당된다
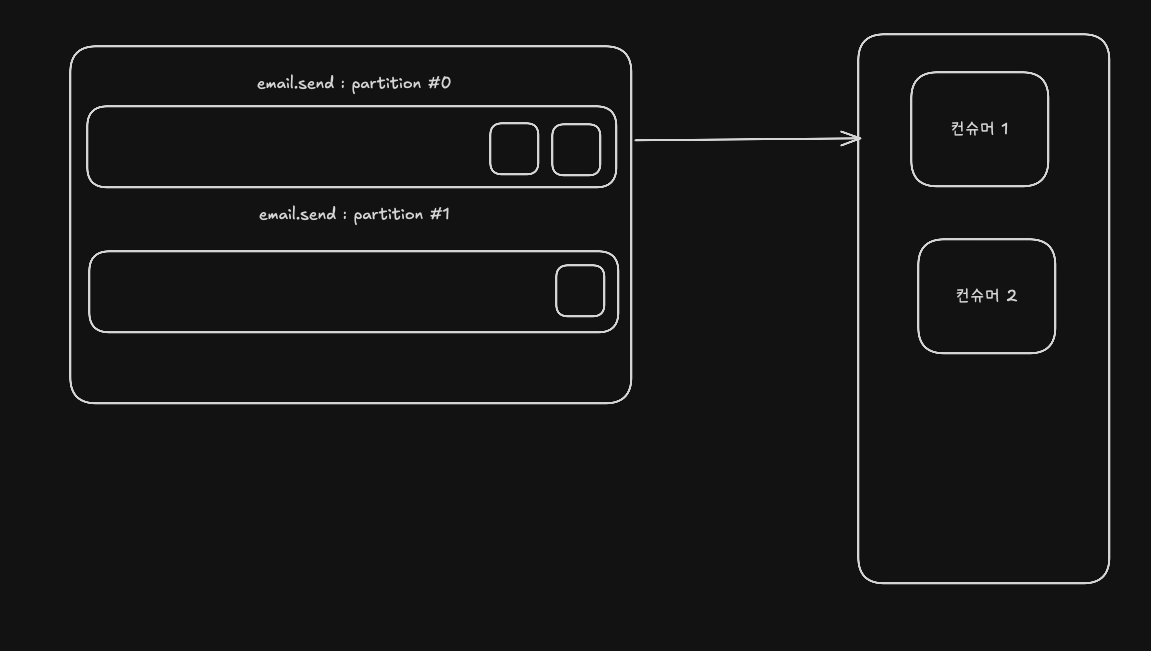

- 여러 컨슈머가 하나의 파티션의 메시지를 같이 처리할 수는 없다
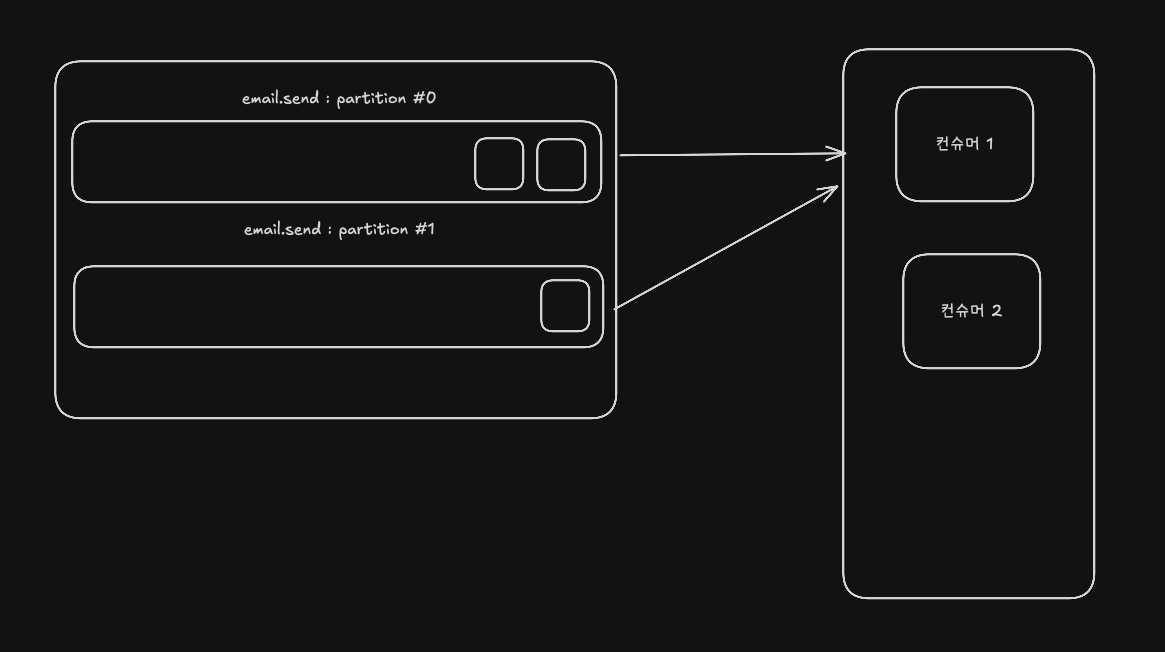
- 여러 컨슈머가 하나의 파티션의 메시지를 같이 처리할 수는 없지만, 하나의 컨슈머가 여러 파티션을 처리하는건 가능하다
기존 토픽의 파티션 수 줄이기
- 기존 토픽의 파티션 수를 늘리는 건 가능하다
kafka-topics --bootstrap-server <kafka 주소> --alter --topic <토픽명> --partiotions <적용할 파티션 수>
- 그러나 늘어난 파티션 수를 다시 줄이는 건 불가능 하다
- Kafka 에서는 파티션 수를 늘릴 수는 있지만 줄일 수는 없게 만들어놨다. 파티션을 줄이는 과정에서 내부적으로 문제(데이터 손실, 성능 저하 등)가 많이 발생하기 때문이다
- 그래서 파티션을 줄이고 싶다면 새로운 토픽을 생성해서 파티션 수를 다시 설정하고 기존 토픽을 새로운 토픽으로 마이그레이션 해야한다
- 그러므로 처음 파티션 수를 설정할 때 신중하게 설정하는 걸 권장한다
파티션을 통한 메시지 발송
key가 포함되지 않은 메시지를 넣을 경우
- 테스트 환경
- topic :
email.send - partition : 3
- topic :
- 스티키 파티셔닝 방식으로 메시지를 분배한다
- 배치 단위로 처리하기 위해 하나의 파티션에 메시지가 일정량이 채워져야만 그 다음 파티션에 메시지를 저장

- 배치 단위로 처리하기 위해 하나의 파티션에 메시지가 일정량이 채워져야만 그 다음 파티션에 메시지를 저장
- 파티션 #0 에서만 메시지 소비 (일정량이 채워져야 다음 파티션으로 메시지 저장)
설정을 통해 RoundRobin 방식으로 변경후 메시지 분배
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
partitioner.class: org.apache.kafka.clients.producer.RoundRobinPartitioner
- 세개의 파티션이 돌아가면서 메시지를 소비하고 있다
key 가 포함된 메시지를 넣을 경우
- key 의 해시 값을 기반으로 파티션을 결정해서 메시지를 분배한다
- 같은 key 값을 가진 메시지는 같은 파티션으로 분배된다
여러 개의 컨슈머 서버를 통한 병렬 처리
- 메시지를 병렬적으로 처리하려면 파티션 수에 알맞는 컨슈머 서버를 띄워야 한다
- 파티션 수가 100개이어도 컨슈머 서버가 1대라면 100개의 파티션이 해당 서버에만 할당되어 병렬처리되지 않는다
- 그러므로 적절한 컨슈머 서버를 띄워서 병렬처리를 해야한다
- 할당하는 파티션 개수는 Spring Kafka 에서 적절히 파티션 개수를 할당해준다
한 개의 컨슈머 서버에서 병렬 처리
- 멀티 스레드 기반으로 병렬 처리할 수 있는 파티션 개수를 설정할 수 있다
@KafkaListener(
topics = "email.send",
groupId = "email-send-group",
concurrency = "3"
)- 리스너 컨테이너가 3개의 스레드를 띄워서 같은 컨슈머 그룹으로 파티션 메시지를 병렬로 소비
- 위 방식은
email.send토픽에 대해 동시 처리 스레드를 3개로 처리하도록 설정한 값 이다 - 최대 3개이기 때문에 3개 이상은 병렬로 처리가 불가능하다
KafkaListener는Spring-Kafka전용 리스너 컨테이너 (기본ConcurrentMessageListenerContainer) 내부에서 관리하는 독립적인 스레드 풀을 사용한다- 즉 실제로는
KafkaMessageListenerContainer를 여러 개 띄우고 각각 별도의 전용 스레드로 실행된다- 이 스레드들은 컨슈머 단위로 유지된다
- 기본적으로
SimpleAsyncTaskExecutor를 사용해서 스레드를 만들어 실행
- 아무 설정도 안하면 컨슈머 그룹안에서 딱 1개 스레드만 메시지를 처리한다
적정 파티션 개수
- 처리가 지연되는 메시지가 생기지 않는 선에서 파티션을 최소로 설정하는 것
- 프로듀서가 보내는 메시지 량 <= 하나의 스레드가 처리하는 메시지 량 * 파티션 수
- 몇개의 스레드를 사용해야 처리량이 가장 높아지는 지 측정
- 부하 테스트를 하여 측정
- 예시) 100개의 스레드를 활용하는 게 가장 효율적이라고 측정했다고 가정
- 하나의 컨슈머 서버가 처리할 수 있는 최대 처리량(Throughput) 을 알아내기
- 최대 처리량이 얼마나 되는 지 측정해야 한다
- 예시) 하나의 컨슈머 서버(100개의 스레드 활용)가 1초에 처리할 수 있는 처리량이 30이라는 걸 알아냈다고 가정, 즉 1개의 스레드가 1초당 0.3개의 요청을 처리한다는 뜻
- 프로듀서가 보내는 평균 메시지 값 알아내기
- 사용자가 1초당 평균적으로 얼마나 요청을 보내는지 측정 혹은 예상
- 예시) 사용자가 평균적으로 1초당 100개의 메일을 보낸다고 가정
- 처리가 지연되지 않는 선에서 파티션 개수 계산
- 평균 메시지량이 어느정도 초과할 것을 예상해서 계산
- 예시) 평균 메시지량이 초과할 것을 예상해서 120 정도로 잡고 아래 공식을 통해 적정 파티션 개수가 400 이라는 걸 알아냄
- 120 (프로듀서가 보내는 메시지량) = 0.3 (하나의 스레드가 처리하는 메시지량) * 400 (적정 파티션 개수)
컨슈머 랙 (Consumer Lag)
Lag
- 컴퓨터가 느려지면 "랙 걸린다" 라고 자주 하는데 이때 랙이 바로 "Lag" 이다
- 즉 Lag 는 지연, delay 라는 의미이다
언제 발생하는가?
- 프로듀서의 메시지 생산량보다 컨슈머의 메시지 처리량이 작을 때 컨슈머 랙(Consumer Lag)이 발생한다
- 메시지가 3초에 3개씩 생기는데 1초에 메시지를 1개씩 밖에 처리하지 못한다면 1초 당 2개의 메시지가 계속해서 쌓일 것 이다
- 실제 현업에서는 컨슈머 서버에서 장애가 발생했을 때 혹은 외부 API 를 활용한다면 여기에 대한 지연, 갑작스러운 요청 등에서 발생하게 된다
Consumer Lag 모니터링
- 컨슈머 그룹 정보를 통해 Lag 를 확인할 수 있다

- 현업에서는 계속해서 카프카에 접속하여 명령을 요청할 수 없으므로 외부 모니터링 툴을 사용한다
- Datadog, Burrow, Prometheus/Grafana
- 혹은 매니지드 서비스 에서 제공하는 모니터링 기능을 활용할 수 있다
- 대표적으로 AWS MSK, Confluent Cloud 가 있다
'학습일지 > Kafka' 카테고리의 다른 글
| [Kafka] Replication, Leader (0) | 2025.09.24 |
|---|---|
| [Kafka] RetryableTopic, DLT (0) | 2025.09.23 |